
지난번에는 프로야구 크롤링을 해 보았다.
하지만 나는 정규시즌 성적을 크롤링하기를 원하는데, 지금은 정규시즌은 끝났고, 플레이오프를 진행하고 있다.
그럼 우리가 원하는 정규시즌 데이터를 얻기 위해서는 선택 메뉴에서 'kbo 정규시즌'을 선택을 해서 크롤링을 해야 한다.
하지만 그렇게 선택해도 개발자 도구에서는 html의 변화가 없다.
이럴 때 사용하는 것이 셀레니움(selenium) 모듈이다.
먼저 모듈을 설치하자
pip install selenium그다음 모듈을 import 해주는데 나는 여기서 4가지를 사용했다.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
import pandas as pd
import time셀레니움이 웹브라우저를 컨트롤하며 크롤링하는 기능이기 때문에 웹브라우저를 자동으로 켜주고 원하는 페이지로 들어가게 해주는 모듈들도 필요하다.
webdriver는 셀레니움을 통해 크롤링을 할 때 웹페이지를 읽는 역할을 하고,
ChromeDriverManager는 인터넷 프로그램이라고 생각한다.
ChromeDriverManager를 사용할 때 두 가지 방법이 있는데, 지금처럼 import 해주는 방법이 있고 아니면 프로그램을 다운로드하여 실행하는 방법이 있다.
만약 지금처럼 한다면
# 크롬이 설치 되어있어야 함
driver = webdriver.Chrome(ChromeDriverManager().install())이렇게 자동으로 설치해주는 코드를 쓰면 되고, 다운로드한다면
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 107, please download ChromeDriver 107.0.5304.18 If you are using Chrome version 106, please download ChromeDriver 106.0.5249.61 If you are using Chrome version 105, please download ChromeDriver 105.0.5195.52
chromedriver.chromium.org
여기서 최신 파일을 다운로드한 후
driver = webdriver.Chrome('D:\Python\chromedriver.exe')이렇게 하면 된다.
하지만 파일을 다운받아서 하면 업데이트될 때마다 새로 받아야 하는 귀찮음이 있어서 첫 번째 방법을 사용하는 걸 추천한다.
select와 by는 드롭박스 선택을 위한 기능들이다.
다음 pandas는 데이터 프레임을 위한 기능이고, time은 조금 있다가 설명한다.
먼저 홈페이지부터 들어가 보자
프로야구 기록실을 주소로 드라이버를 실행한다.
driver.get('https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx?sort=HRA_RT')그리고 실행을 하면 크롬 브라우저로 괄호 사이에 적은 주소로 이동하게 된다.
정확하게는
# 크롬 브라우저 실행
driver = webdriver.Chrome(ChromeDriverManager().install())
# 홈페이지 기록실로 이동
driver.get('https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx?sort=HRA_RT')이라고 생각하면 된다.
그러면 전에 봤던 홈페이지로 이동을 하게 되는데 여기서 우리는 정규시즌으로 들어가야 한다.
F12를 눌러 개발자 모드로 들어간 후, 드롭박스 위치를 찾는다.
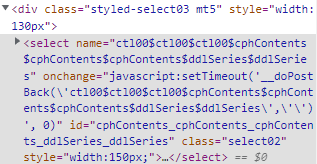
해당 드롭박스의 아이디는 'cphContents_cphContents_cphContents_ddlSeries_ddlSeries' 이고, 텍스트는 'KBO 정규시즌'이다.
먼저 해당 드롭박스를 선택하고 KBO 정규시즌을 선택한다.
# 정규시즌 select 태그(드롭다운) 선택
dropdown = Select(driver.find_element(By.ID, 'cphContents_cphContents_cphContents_ddlSeries_ddlSeries'))
# 정규시즌 선택
dropdown.select_by_visible_text('KBO 정규시즌')실행하면 실행되어있던 크롬 브라우저가 KBO 정규시즌 페이지를 자동으로 선택하여 이동하게 된다.
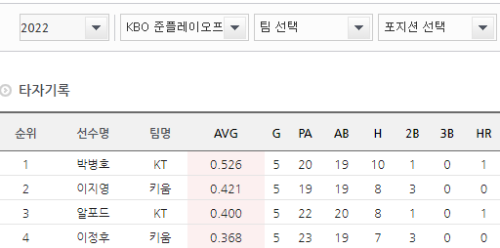

이렇게 바뀌게 된다.
그 다음 바뀐 페이지에서 크롤링을 하면 된다.
먼저 해당 페이지에서 선수 기록 테이블을 찾고 출력해본다.
driver.find_element(By.TAG_NAME, 'table')

이런식으로 제대로 정리가 안되어있다.
하지만 그 전에 그냥 저렇게 코드를 실행시키면 정규시즌 성적이 아닌 그 전인 플레이오프 성적이 나오는데 그 이유는
원래 순서가 드롭다운 클릭 -> 페이지 이동 -> 크롤링 인데
코드가 쉬지않고 바로 실행되다보니 페이지를 이동하기 전에 크롤링이 실행되서 그렇다.
그렇기 때문에 전에 import한 time 기능을 써서 약간의 딜레이를 넣어야 한다.
time.sleep(.5)
driver.find_element(By.TAG_NAME, 'table').text그러면 정상적으로 원하는 성적을 가져올 수 있다.
이어서 해 보자면 지금 저렇게 원하는 대로 정렬이 안되어 있기 때문에 우리가 원하는 모습으로 바꿔줘야 한다.
자세히보면 선수 한 명의 성적이 다 출력되면 \n이 되는 것을 볼 수 있다.


그럼 여기서 우리는 먼저 엔터(\n)를 기준으로 한 번 나눠주면 된다.
driver.find_element(By.TAG_NAME, 'table').text.split('\n')

그럼 이렇게 선수 한 명당 한 줄로 나눌 수 있다.
그 다음은 우리가 이 데이터를 데이터 프레임으로 만들것이기 때문에, 기록 하나하나를 분리해주어야 한다.
데이터는 스페이스(' ')를 기준으로 하고 있다.
a = driver.find_element(By.TAG_NAME, 'table').text.split('\n')
b = []
for i in range(len(a)):
b.append(a[i].split(' '))
b

그럼 이렇게 선수 한 명당 한 줄이며, 데이터 하나하나가 분리된 것을 볼 수 있다.
이제 이 코드를 줄여보자
data = [x.split(' ') for x in driver.find_element(By.TAG_NAME, 'table').text.split('\n')]driver.find~부분의 \n으로 나눈 데이터 하나를 x에 넣고 그 x를 스페이스로 분리하여 data에 넣는다는 의미다.
이제 만든 data로 데이터 프레임을 만들어 보자
temp = pd.DataFrame(data)

그럼 이렇게 데이터가 잘 들어간 것을 볼 수 있다.
이제 전에 했었던대로 index와 column을 바꿔보자
# columns 가져오기
player_thead = driver.find_element(By.TAG_NAME, 'tr').text.split(' ')
# columns 바꾸기
temp.columns = player_thead
# 첫 번째 행 지우기
temp = temp.drop(0, axis=0)
# index 바꾸기
temp = temp.set_index ('순위')
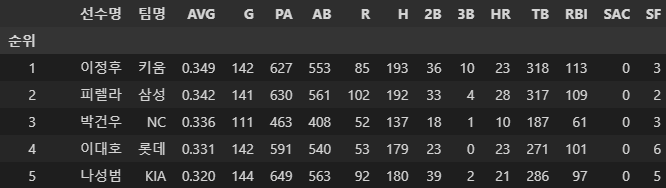
이러면 완성입니다.
이 후에 보면 현재 기록 페이지가 두 페이지로 나뉘어 있습니다.
이젠 다음 페이지를 크롤링하고 만든 데이터 프레임에 연결해 보겠습니다.
# 2페이지 클릭
driver.find_element(
By.ID, 'cphContents_cphContents_cphContents_ucPager_btnNo2'). click()
time.sleep(.5)
# 데이터 저장
data2 = [x.split(' ') for x in driver.find_element(
By.TAG_NAME, 'table').text.split('\n')]
# 데이터프레임
temp2 = pd.DataFrame(data2)
temp2.columns = player_thead
temp2 = temp2.drop(0, axis=0)
temp2 = temp2.set_index('순위')
이전과 같은 방법으로 2페이지 버튼 위치를 찾고 클릭해줍니다.
그 다음 테이블 위치를 찾고 크롤링 한 다음 데이터 프레임을 만들었습니다.
그리고 columns과 index도 바꾸었습니다.
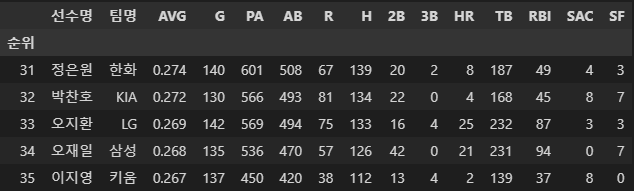
잘 되었으니 합쳐봅시다.
temp3 = pd.concat([temp, temp2])
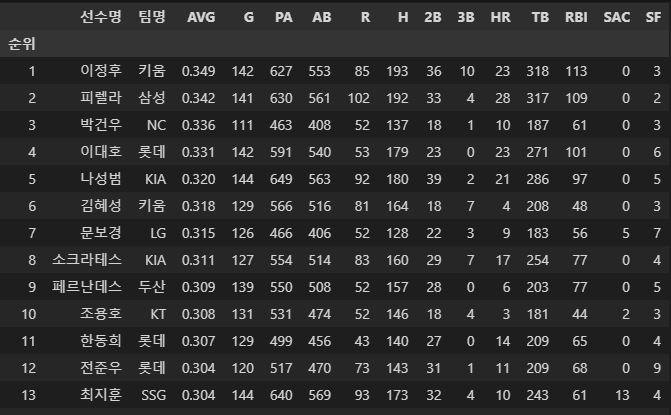
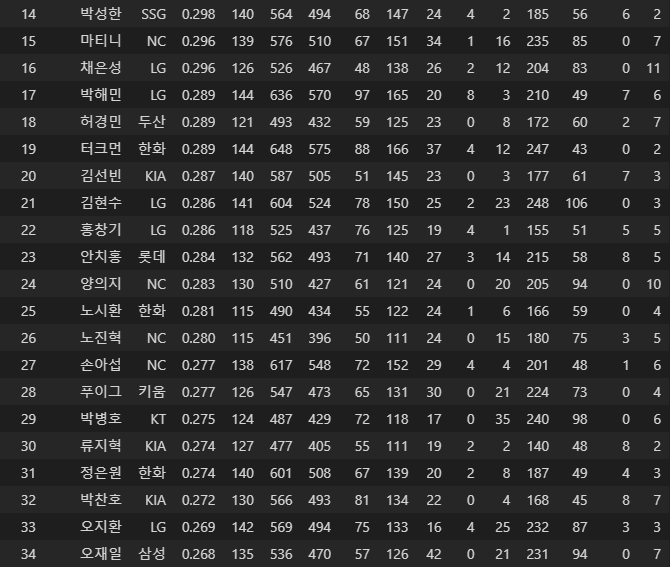
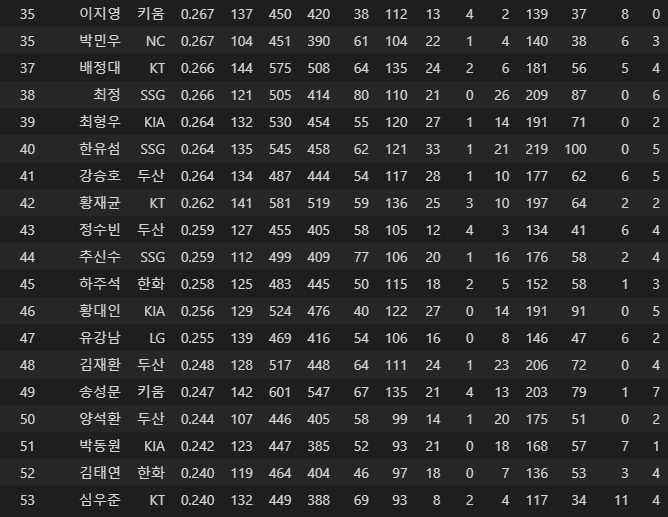
잘 합쳐진 것을 볼 수 있습니다.
'이것저것 개발' 카테고리의 다른 글
| 파이썬으로 프로야구 크롤링하기-1 (0) | 2022.10.21 |
|---|